CDC 란?
- CDC = Change Data Capture
- 데이터의 변경사항을 추적하여 저장하거나 해당 변경사항에 응답해야하는 다른 시스템과 서비스에 경고하는 데이터 통합패턴
- 예를 들어 배민에서는 CDC 패턴을 통해 내부 업무 요청건에 변경사항이 생겼을 경우 실시간 알람을 보내는 서비스를 구축했다. (https://techblog.woowahan.com/10000/)
사용 예시
- 서비스 중단 없이 데이터 이전 (On-premise To Cloud)

- DataWarehouse로의 실시간 데이터 적재

- 원본DB와 캐시간의 데이터 일관성 보장

- 검색 인덱스 실시간 구성
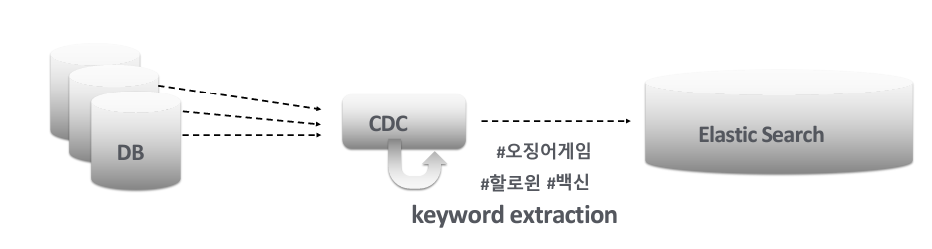
사용 Tool 예시
OLTP
- RDBMS : Mysql, Postgresql, ...
- NoSQL : MongoDB, Elasticsearch, ...
Capture
- Kafka
- 특징
- Pulling 방식으로 데이터를 가져오기 때문에 OLTP DB의 부하를 줄일 수 있다.
- 적어도 한번 전송방식을 지키기 때문에 데이터 유실을 막을 수 있다.(데이터 중복 위험성 존재)
- Debezium Connector를 통해 변경 데이터를 수집할 수 있다.
- Debezium Connector 지원 DB : MongoDB, Mysql, Postgresql, SQL Server, Oracle, Db2, Cassandra, Spanner, Vitess(Incubating), JDBC(Incubating), Informix(Incubating)
- 특징
DW
- 보통 사내에서 이용중인 OLAP DB를 주로 사용한다.
- 실시간 데이터 적재 시 Insert 성능이 중요하며, 임시적재를 통해 배치적재를 한다면 코어타임의 DB부하를 줄일 수 있다.
- 예시 : Redshift, BigQuery, DeltaLake, Iceberg, ...
CDC 구축 예시
배달의 민족
- 구축목표 : 기존의 프론트 코드에서 발송하던 알림을 백엔드 처리로 변경하여 세일즈 매니저의 업무 상태 변화를 안정적으로 전달하기 위함
- 기존 프론트 방식의 문제
- 네트워크 문제로 알림 발송 누락
- 알림 발송 이후 요청 건의 상태 변경에 실패하면 실제 데이터와 알림이 맞지 않음
- 구축 아키텍처

- 구축 시 유의 점
- Debezium MySQL Connector를 연동 시 binlog dump thread가 Aurora MySQL 클러스터 스토리지의 binlog를 읽을 때 잠시 Lock을 걸게됨. 따라서 binlog dump thread의 부하가 심해질 경우 Insert, Update, Delete, Commit 등 DML관련 지연이 증가하고 장애 가능성이 높아짐.
- Kakfa 메시지는 중복의 위험성이 있음 (배민에서는 Redis Cache를 활용하여 해결)
카카오페이
- 구축목표 : 데이터 실시간 분석을 위해 Oracle → MongoDB CDC 파이프라인 구축
- 기존 방식의 문제점 및 향후 목표
- 여러 데이터 베이스에 분산 저장된 데이터의 활용이 힘듦
- 향후 kakfa를 주축으로 한 CDC Pipeline을 구성하여 복잡한 CDC 솔루션(GoldenGate, jdbcAdapter,..)들을 하나로 정리 예정
- 구축 아키텍처
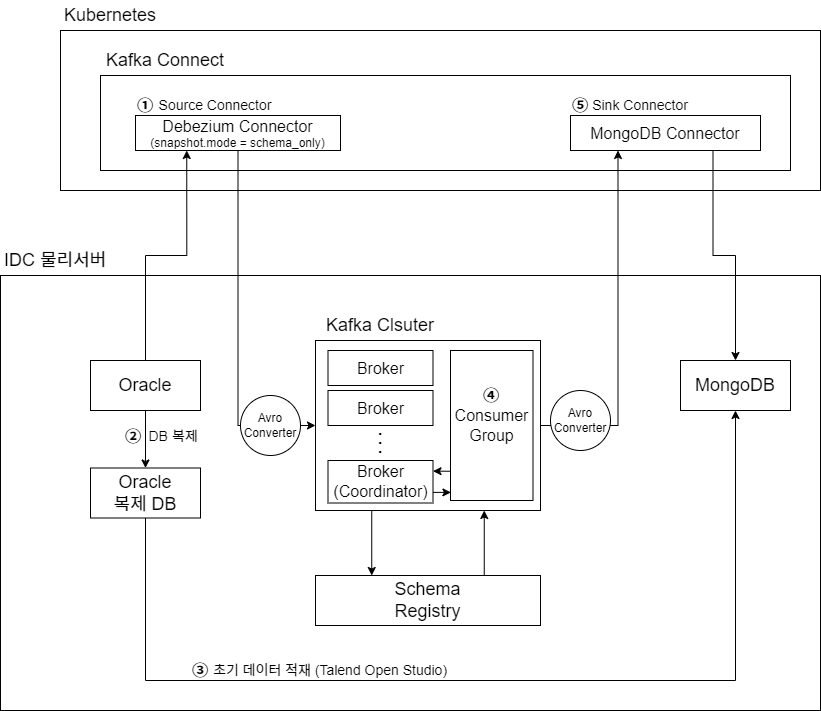
- 구축 시 유의점
- 초기 Oracle DB migration
- 운영DB 및 서비스에 부담을 주지 않기 위해 Primary가 아닌 Secondary 환경에 복제 DB 생성 후 데이터 유실을 막기위해 Source Connector 생성 후 Oracle DB 복제본을 생성
- 총 6TB, 130억건, 12개의 테이블 중 3개가 90%이상 차지하는 대용량의 데이터
- Talend Open Studio를 활용하에 복제 데이터를 생성
- Export : Oracle DB의 데이터를 2만건 씩 pasing하여 json 포맷파일로 변환 (data type을 유지하기 위해 json 포맷사용, json parsing 시 많은 양의 메모리가 사용됨. = 페이징처리+병렬처리)
- Import : 생성된 json 포맷의 파일을 MongoDB에 적재
- 초기 Oracle DB migration
네이버페이
- 기존 방식의 개선점 및 구축목표
- 부하를 더 잘 견딜 수 있는 MSA 구조로의 변환 필요성
- 각 도메인 DB 분리
- 도메인 DB간의 데이터 동기화
- 도메인EB의 scale-out 필요성
- 데이터 저장 비용 효율화
- 목표1. 도메인 DB 떼어내기
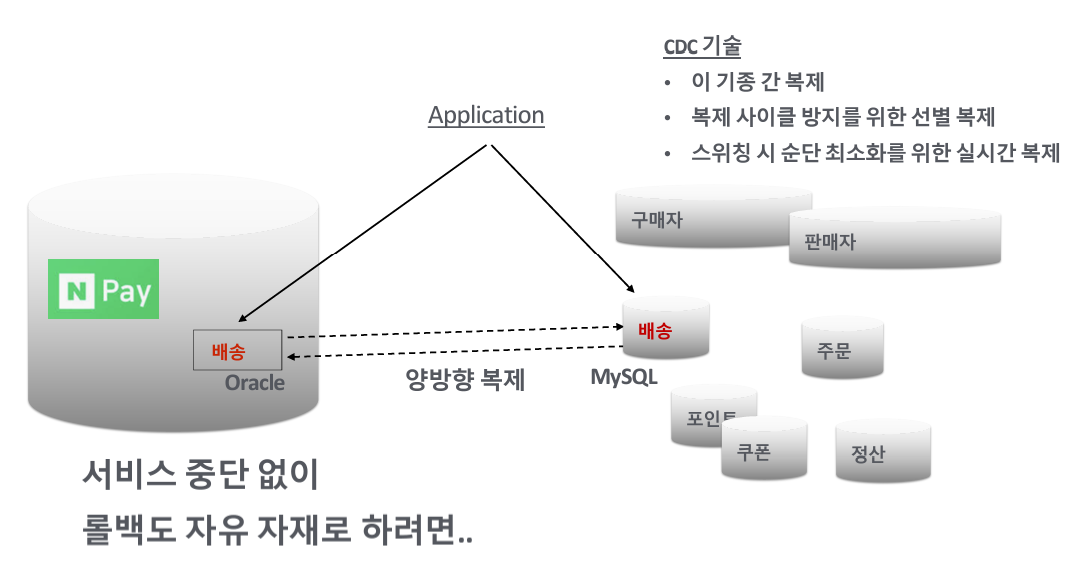
- 목표2.도메인 DB간 데이터 동기화

- 목표3.도메인 DB 비용 최적화

- 구축 시 유의점 (해당 부분의 내용이 자세하게 다루어져 있어 좀 더 공부가 필요하다. 이해가 잘 안됨 ㅠ)
- shared mysql cluster ⇄ Oracle
- Sharding을 위한 Logic View + Meta Data 처리
- Shard Rebalance로 인한 내부 부하 및 순서보장
- 즉각적인 Rollback을 위한 성능 최적화
- 안정적인 복제를 위한 고가용성
- shared mysql cluster ⇄ Oracle
토스
- 목표
- 기존에 구축한 CDC의 운영 평가 지표 선정
- 평가지표 (Target System에 데이터 저장 CDC Pipeline)
- Source-to-Target Latency : 원천 데이터베이스에서 Target System으로 Event를 보내는데 걸리는 시간
- Events Per Second : 초당 처리할 수 있는 데이터 양
- CDC Pipeline Scalability : 새로운 CDC 파이프라인을 만드는데 소요되는 시간
- Data Consistency : CDC Pipeline을 통해 만든 데이터의 정합성
Source-to-Target Latency

- Tier
- Tier 1. 실시간(300ms) : 서비스용 데이터 System
- Tier 2. Near Realtime(10 seconds) : 서비스용 알람
- Tier 3. 10 minutes : 지표와 관련된 서비스
- Tier 4. 1hour : 분석용 데이터
- 확인 방법
- end-to-end pipeline의 latency 구하기 : sink precess time(Target System에 데이터를 write한 시간) - source.ts_ms(원천데이터베이스에 event 발생시간)
- 전체 파이프라인에 성능 확인 후 기대이하의 성능일 경우 MiliSecondsBehindSource / kafka Consumer lag / Sink Process Time 확인
Events Per Second
CDC Pipeline Scalability
Data Consistency
참고
- 초기데이터 통합부터 CDC 환경 구축기(카카오페이증권) : https://tech.kakaopay.com/post/kakaopaysec-mongodb-cdc/
- Debezium Connector 지원 : https://debezium.io/documentation/reference/stable/connectors/index.html
- CDC 구축을 통한 서비스 보완(배달의민족) : https://techblog.woowahan.com/10000/
- 막힌 데이터의 혈을 뚫자! Pay 플랫폼 CDC 적용 사례(네이버페이) : https://deview.kr/2021/sessions/495
'데이터 > Architecture' 카테고리의 다른 글
| Star Schema 란? (0) | 2024.08.10 |
|---|---|
| Lambda Architecture 란 (0) | 2024.07.29 |


댓글