문서 작성시 Batch Architecture를 Lambda Architecture와 혼동하여 용어를 잘못기재했다... (진짜 똥멍청이)
Lambda Architecture에 대한 이해도가 낮아서 발생한 일이라 생각하고
다음부터는 이런 일을 방지하고자 Lambda Architecture에 대한 정의를 정리해서 머리에 콱 박아놓을 예정이다.
(용어를 사용할 땐 꼭 확실히 이해한 뒤에 사용하자!!)
Lambda Architecture
정의
- Batch Process와 Stream Process 를 모두 활용하여 대량의 데이터를 처리하도록 설계된 아키텍처
- 대량의 데이터를 실시간으로 분석하기 어려우므로 Batch를 통해 만들어진 데이터와 실시간 데이터를 혼합하여 사용하는 방식.
구성요소
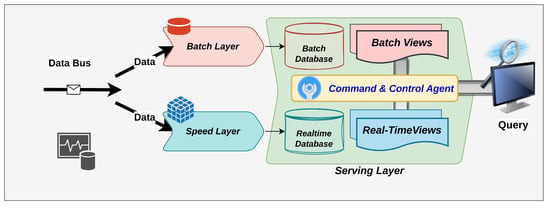
① Batch Layer
- Batch를 통해 대용량의 데이터를 미리 계산한다.
- 미리 계산한 데이터 외에도 데이터 복구 혹은 새로운 view 생성을 위한 원본(raw) 데이터도 함께 저장한다.
- 저장소 : Apache Hadoop MapReduce, Snowflake, Redshift, Big Query, 등등 (대부분의 OLAP DB가 해당)
② Speed Layer
- 실시간으로 데이터 스트림을 처리한다.
- 가장 최근의 데이터에 대한 실시간 view를 제공하여 지연시간을 최소화 하는 것을 목표로 한다.
- Batch Layer의 데이터와 현재의 데이터의 "Gap"을 줄이는 역할을 한다.
- 데이터 스트림 처리 s/w : Apache Kafka, Amazon Kinesis, Apache Flink, Apache Spark, 등등
- 저장소 : 주로 NoSQL DB
③ Serving Layer
- Batch Layer와 Speed Layer에서 생성된 데이터를 저장하는 공간.
- Batch Layer에서 생성된 데이터 DB와 Speed Layer에서 생성된 데이터 DB가 종류는 다를 수 있으나 Join과 같은 트랜잭션을 통해 통합 조회가 가능해야한다! (해당 부분이 내가 이해를 잘못하고 있었던 부분이다. 보통 NoSQL DB와 SQL DB는 호환이 되지 않는다...)
- aws 환경에서는 Dynamo DB를 Speed Layer DB로 사용하고 Redshift를 Batch Layer DB로 사용한다면 Athena를 통해 통합쿼리를 쓸 수 있을것 같다! (Athena 와 Dynamo DB 연동 가능)
필요한 상황
Lambda Architecture는 여러 계층을 관리하기 때문에 더 복잡하다. 배치 및 실시간 처리의 이점이 복잡성보다 더 큰 경우 선택해야 한다. 이후 데이터 디버깅 시 Batch Layer와 Stream Layer 모두를 점검해야하기 때문에 관리포인트가 2배가 된다.
- 사기 감지: 과거 거래 데이터를 분석(일괄 처리 계층)하고 실시간 거래에서 이상을 감지(속도 계층).
- IoT 데이터 처리: IoT 장치에서 실시간 데이터를 처리(속도 계층)와 동시에 과거 센서 데이터를 집계하고 분석(일괄 계층)
- 고객 분석: 통찰력을 위해 기존 고객 데이터를 분석(일괄 처리 계층)하는 동시에 사용자 행동에 따른 실시간 추천을 제공(속도 계층).
참고
- lambda architecture란 : https://en.wikipedia.org/wiki/Lambda_architecture
- Lambda architecture 사용 사례 : https://medium.com/@vinciabhinav7/lambda-architecture-a-big-data-processing-framework-introduction-74a47bc88bd3
'데이터 > Architecture' 카테고리의 다른 글
| CDC Architecture (0) | 2024.08.10 |
|---|---|
| Star Schema 란? (0) | 2024.08.10 |


댓글