데이터/Spark
Spark 병렬처리 성능 테스트 사례
Sunyoung95
2024. 7. 14. 21:18
실제 대용량의 데이터를 가지고 Spark를 테스트해볼 수 있는 환경이 아니라
이전에 정리했던 내용을 직접 실습하기에는 어려운 점이 있어서 아쉬웠다.
그런데 AWS 환경에서 병렬 성능 테스트를 한 글을 찾아서 해당 글을 토대로 내용을 정리해볼 예정이다.
이번 글을 정리하며 만약에 실제로 대용량의 데이터를 이관할 경우 Spark의 병렬성을 어떻게 올릴 수 있는지 전략을 배우는 것이 목표이다.
참조한 글
AWS Glue JDBC 병렬 처리 성능 테스트
⇒ 컬럼 중 OL_D_ID가 Number type (DynamicFrame의 hashexpression 사용 가능)이고 아래와 같이 10개의 UNIQUE한 값이 약 4백만건씩 고르게 가지고 있기 때문에 해당 컬럼을 파티셔닝 기준으로 세웠다. ⇒ 원래의
medium.com
Job 제출 시 Executor 활용 방식
- 데이터 크기 : 2.9GB
- Row Count : 40,183,307 (약 4000만 건)
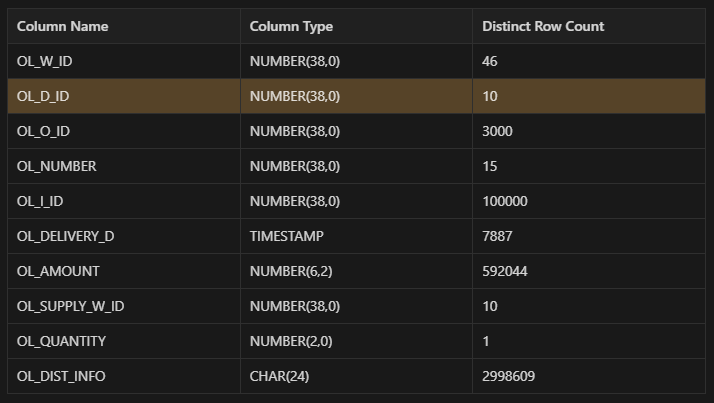
Partitioning 기준 : OL_D_ID
→ 10개의 Unique한 값이 약 4백만건씩 고르게 분포되어있음.
Test 결과 (AWS Glue 기준)
| G.1.X | ||||||
| Worker 수 | 10 | 12 | ||||
| Worker 스펙 | 4 Core 16 GB |
4 Core 16 GB |
||||
| Driver / Executor Memory |
10 GB | 10 GB | ||||
| Executor Core | 4 Core | 4 Core | ||||
| 동시최대 Task 수 | 4 x 10 | 4 x 12 | ||||
| Task 당 Memory | 10 GB / 4 = 2.5 GB | 10 GB / 4 = 2.5 GB | ||||
| read Partiton | X | OL_D_ID | OL_W_ID | |||
| read Partiton 개수 | X | 10 | 46 | |||
| read/write 방식 | Dynamic Frame | Dataframe | Dynamic Frame | Dataframe | Dynamic Frame | Dataframe |
| 처리 방식 | • 1개의 worker가 데이터를 전부 가져와서 다른 worker에 분배 | • 1개의 워커가 4천만건을 전부 read/write • executor 10개 중 1개만 사용됨 |
• 3개의 worker가 각각 4/4/2 개 씩 task를 처리 • Job 수행 시 worker마다 DB Connection을 생성하므로 이를 최소화하는 방향으로 진행 |
• 3개의 worker가 각각 4/4/2 개 씩 task를 처리 • Job 수행 시 worker마다 DB Connection을 생성하므로 이를 최소화하는 방향으로 진행 |
• 10개의 Partition으로 나눈 것보다 성능이 떨어진다. • 각 worker/executor에 균일하게 처리됨 |
• 같은 Partitoning기준으로 Dynamic Frame보다 성능이 좋음(Executor의 core 수를 계산하여 최대한 많은 task가 병렬처리 될 수 있도록 파티션 수를 계산했기 때문) • 각 worker/executor에 균일하게 처리됨 |
| 처리 시간 | 5 min 19 sec | 12 min 25 sec | 2 min 34 sec | 4 min 13 sec | 4min 25 sec | 2 min 44 sec |
| Shuffle | 약 4000만 건 | X | X | X | X | X |
| Spill (Mem/Disk) | 4.4 gb / 1gb | X | X | X | X | X |
| 생성 task 수 | 20 | 1 | 10 | 10 | 46 | 46 |
| 활성화 worker 수 | 10 | 1 | 3 | 3 | 12 | 12 |
| output file 수 | 20 (생성task 수와 동일) |
1 | 10 (생성task 수와 동일) |
10 | 46 | 46 |
결론
- dynamic frame은 AWS의 Glue에서만 제공되므로 일반적인 Spark를 생각하면 Dataframe기준으로 결과를 비교해봐야한다.
- DataFrame을 기준으로 가장 성능이 좋은 것은 46개의 Paritioning을 진행했을때
- 따라서 Executor의 총 Core 수에 맞게 Task 수를 생성하도록 Partitioning을 지정하는 것이 중요하다!
- Task 수 = { (Executor 수) x (Executor Core 수) } x N = Partitioning 수