RDD 란?
- Resilient : RDD lineage 그래프를 통한 fault-tolerant가 빠졌거나, node의 실피로 인한 손상된 파티션을 다시 실행시킨다
- Distributed : 클러스터의 여러 노드에 데이터가 분산되어 저장
- Dataset : 원천 데이터값 혹은 값의 값들로 이루어진 파티션된 collection 데이터
(튜플 혹은 다른 레코드로써 사용될 수 있는 데이터 객체들)
필요한 상황
- 고수준 API에서 제공하지 않는 기능이 필요한 경우(JAVA, Scala에만 해당, Python은 성능손실이 크다)
-> 클러스터의 물리적 데이터 배치를 아주 세밀하게 제어해야 함
-> map, filter, reduce와 같은 하위수준의 변환의 경우 - RDD를 사용해 개발된 기존 코드를 유지해야하는 경우
- 물리적으로 분산된 데이터 (자체적으로 구성한 데이터 파티셔닝)에 세부적인 제어가 필요할 경우
피해야하는 상황
- 필수적인 상황이 아닐경우 RDD 수동생성 지양
- Scala
- 원형 객체를 다룰 때 큰 성능 손실이 발생
- Python
- RDD를 파이썬으로 실행하는 것은 파이썬으로 만들어진 사용자 정의함수(UDF)를 사용해 로우마다 적용하는 것과 동일
- 직렬화과정을 거친 데이터를 파이썬 프로세스에 전달하고, 파이썬 처리가 끝나면 다시 직렬화하여 자바 가상머신에 반환, 파이썬을 이용한 RDD는 높은 오버헤드가 발생
- UDF 선언 시 인터프리터와 JVM사이 커뮤니케이션으로 속도가 저하됨(python의 경우 scala의 2배), 반드시 built in 함수만 쓸 것.
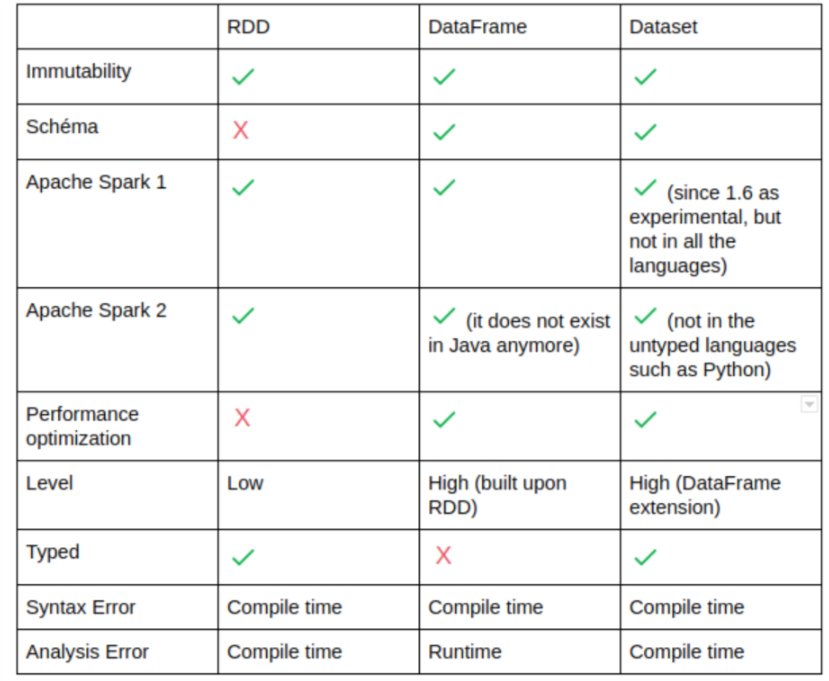
특징
| 특징 | 설명 |
| Instance | 각 record가 로우라는 개념이 아닌 객체 |
| In-Memory | RDD속의 데이터는 가능한 많이, 오래 메모리에 저장되어 있다. |
| 불가변성 (읽기전용) | 한번 생성되고나면 변하지 않는다. transformation 연산을 통해 새로운 RDD로써 만들 수 있다. |
| Lazy evaluated | RDD속의 데이터는 action으로 분류되는 연산자가 실행되기 전까지는 실제 수행되거나 transform되지 않는다. |
| cacheable | data를 캐싱할 수 있다. |
| Paralled (병행처리) | 병행처리가 가능하다 |
| Typed (타입존재) | RDD 레코드는 타입을 가지고 있다. (RDD[long], RDD[int,String] 등등) |
| Partitioned | 레코드들은 논리적인 파티션으로 분할되어있고 클러스터의 여러 노드에 분산저장되어 있다. |
DataFrame 이란?
- SparkSession을 통해 만들어지는 데이터 타입.
- RDB의 테이블과 유사하게 Named Column으로 구성된 분산 데이터 모음
필요한 상황
- 다양한 데이터소스에 접근하여 write / read를 활용한 ETL 작업
- filtering, aggregation, join 등 SQL 테이블과 유사한 작업이 필요한 경우
피해야하는 상황
- 사용자지정함수(UDF)를 선언하여 사용할 경우 속도저하의 원인이 될 수 있다.
특징
| 특징 | 설명 |
| Row | 각 record가 로우라는 개념 |
| Lazy evaluated | RDD속의 데이터는 action으로 분류되는 연산자가 실행되기 전까지는 실제 수행되거나 transform되지 않는다. (실행 전에는 계산/기능에 대한 계보를 저장만 함.) |
| SQL | table과 같은 형식으로 구성되어있기 때문에 SparkSQL을 통해 쿼리를 사용할 수 있다. |
| Table | RDB처럼 테이블을 가질 수 있으며, 테이블에 대한 연산이 가능 |
| Catalyst Optimizer | Catalyst 최적화 프로그램을 통한 내장 최적화는 쿼리의 효율적인 실행을 보장 |
| Schema | DataFrame에는 고유한 스키마가 있으므로 구조화된 데이터와 반 구조화된 데이터처리에 이상적 |
| BI tool 호환성 | Tableau 및 Power BI와 같은 BI도구와 호환되어 데이터 시각화에 용이 |
참고
'데이터 > Spark' 카테고리의 다른 글
| Spark 병렬처리 성능 테스트 사례 (0) | 2024.07.14 |
|---|---|
| Spark Partition 최적화 (0) | 2024.06.23 |
| Spark Cluster 구조 및 작동원리 (0) | 2024.06.09 |



댓글