
자료구조 란?
- 데이터에 효율적으로 접근하고 조작하기 위한 데이터의 조직, 관리, 저장 구조
- 다양한 자료구조가 존재하므로 상황에 맞는 구조를 사용해야한다.
- python에서는 list, tuple, dictionary, set을 활용하여 대부분의 자료구조를 구현할 수 있다.
자료구조의 사용 목적
- 데이터의 조직화를 통한 효율적인 저장, 관리
- 효율적인 메모리 사용
선형 자료구조
순차리스트(Array List)
- Python에서는 List를 통해 구현할 수 있다.
- 논리적인 순서와 물리적인 순서가 같은 구조
- Element (요소) : 배열을 구성하는 각각의 값
- Index (인덱스) : 배열에서 위치를 가리키는 숫자, 값에 대한 유일무이한 식별자
- 장점
- 크기가 정해져 있지 않다. = 데이터를 추가/삭제 시 메모리 공간이 확장/축소 된다.
- 조회 속가 빠르다 = 인덱스 활용
- 단점
- 데이터 추가/삭제 시 시간이 오래걸린다. = 자료의 이동이 생기기 때문에 오버헤드가 발생
연결리스트

- Python에서는 List를 통해 구현 할 수 있다.
- 순서가 있는 데이터들의 모임 (각 노드에 다음 노드의 주소가 저장 됨)
- 배열이 가지고 있는 인덱스라는 장점을 버리고 대신 빈틈없는 데이터의 적재라는 장점을 취한 자료 구조
- Element (요소) : 리스트를 구성하는 각각의 값
- Index (인덱스) : 몇 번째 데이터인가 정도의 의미를 가짐, 유일무이한 식별자가 아님
- 장점
- 크기가 가변적 (null요소는 허용하지 않는다)
- 중간에 데이터 추가/ 삭제시 빠르다.
- 단점
- 조회 속도가 느리다 (인덱스가 순서의 의미만 갖기 때문에, 요소의 위치를 바로 알 수 없다.)
스택 (LIFO, 후입선출)

- Python에서는 List를 활용하여 구현할 수 있다.
- LIFO (Last In, First Out) = 가장 최근에 저장된 값 다음에 저장되며, 가장 최근에 저장된 값이 먼저 나간다
- top 위치의 데이터에 바로 접근이 가능하기 때문에 데이터 삽입, 삭제의 시간 복잡도는 O(1)
- 장점
- top을 통해 접근하기 때문에 데이터 접근, 삽입, 삭제가 빠르다
- 단점
- top 위치 이외의 데이터에 접근할 수 없기 때문에 탐색이 불가능
- 탐색하려 모든 데이터를 꺼내면서 진행해야한다.
- 활용 : 재귀 알고리즘, DFS 알고리즘, 작업실행취소와 같은 역추적 작업이 필요할 때 등
큐 (FIFO, 선입 선출)

- Python에서는 queue 라이브러리를 제공하지만 대부분의 큐와 관련된 자료구조는 list를 통해 구현이 가능하다.
- FIFO (First In, First Out) = 선착순
- rear : 데이터가 삽입되는 곳
- front : 데이터가 제거되는 곳
- front, rear 위치로 데이터 삽입/삭제가 바로 가능하기 때문에 데이터 삽입/삭제의 시간 복잡도는 O(1) 이다.
- 장점
- front, rear를 통해 접근하기 때문에 데이터 접근, 삽입, 삭제가 빠르다.
- 단점
- front, rear 위치 이외의 데이터에 접근할 수 없기 때문에 탐색이 불가능
- 탐색하려면 모든데이터를 꺼내면서 진행해야한다.
- 활용 : 데이터 입력순으로 처리할 때, BFS 알고리즘, 프로세스 관리, 대기순서 관리
데크

- Python에서는 collections 모듈에서 deque를 사용하여 구현할 수 있다.
- front, rear 양쪽으로 삽입 및 삭제가 가능한 자료구조
- 선언 이후 크기를 줄이거나 늘릴 수 있는 가변적 크기를 갖는다.
- 중간에 데이터가 삽입 될 대 다른 요소들을 앞, 뒤로 밀 수 있다.
- 시간복잡도는 삽입/삭제 연산 시 O(1), index를 통한 요소 탐색 시 O(1)
- 장점
- 데이터의 삽입/삭제가 빠르고 앞/뒤에서 삽입/삭제가 모두 가능하다
- 가변적 크기
- index를 통해 임의의 원소에 바로 접근이 가능하다
- 단점
- 중간에서 삽입, 삭제가 어렵다
- 스택/큐에 비해 비교적 구현이 어렵다
- 활용 : 데이터 크기가 가변적일 때, 데이터를 앞/뒤에서 모두 삽입/삭제하는 과정이 필요할
비선형 자료구조
트리

- 노드(데이터)들을 간선으로 연결한 계층형 자료 구조
- Node (노드) : 데이터
- Edge (간선) : 노드들을 연결해주는 선
- 사이클이 존재하지 않음 (사이클이 만들어진다면 그래프이다)
- 모든 노드는 자료형으로 표현이 가능하다.
- 루트에서 한 노드로 가는 경로는 유일한 경로 뿐이다.
- 노드의 개수가 N개면 간선은 N-1개를 가진다.
그래프

- 연결되어있는 원소간의 관계를 표현한 자료구조
- Vertext (정점) : 연결할 객체
- Edge (간선) : 객체를 연결하는 선
- 그래프 G를 G=(V, E)로 정의 (V = 정점의 집합, E = 간선들의 집합)
- 표현방법
- V(G1)={0,1,2,3,4,5}
- E(G1)={(0,2), (0,4), (0,5), (1,4), (1,5), (2,3), (2,4), (4,5)}
그 외
Hash Table
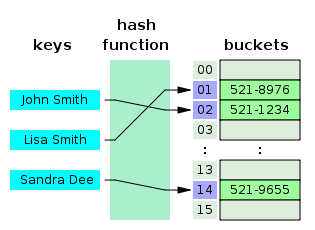
- Python에서는 dictionary가 Hash Table 구조로 구현되어있다.
- 해시 함수를 사용하여 key를 해시값으로 매핑하고, 해시값을 색인(인덱스) 또는 주소삼아 데이터를 key와 함께 저장
- Key & Value 로 이루어진 자료구조
- Key
- 고유한 값
- key 값을 그대로 저장소의 색인으로 사용할 경우 key의 길이만큼 정보를 저장할 공간을 따로 마련해야하기 때문에 (key의 길이가 제각각 일 수 있음), 고정된 길이의 해시로 변경 = hash function
- Hash Function
- key를 고정된 길이의 hash로 변경해주는 역할을 한다.
- 서로 다른 key가 hashing 후 같은 hash 값이 나오는 경우가 있다. 이를 해시 충돌이라고 부른다.
- 해시 충돌 발생확률이 적을 수록 좋다.
- 해시 충돌이 균등하게 발생하도록 하는것도 중요하다.
- 모든 키가 같은 해시값이 나오게 되면, 데이터 저장 시 비효율성도 커지고 보안이 취약해져서 좋지 않다.
- Value
- 저장소(버킷, 슬롯)에 최종적으로 저장되는 값으로, hash와 매칭되어 저장되어진다.
- Hash Table
- 해시함수를 사용하여 키를 해시값으로 매핑하고, 이 해시값을 주소 또는 색인 삼아 데이터(value)를 key와 함계 저장하는 자료구조
- 데이터가 저장되는 곳을 버킷, 슬롯 이라고 한다.
- 장점
- 삽입 / 삭제 / 검색의 과정에서 모두 평균적으로 O(1)의 시간복잡도를 가지고 있다. (Key-Value가 1:1로 매핑되어있기 때문)
- 단점
- 해시 충돌이 발생
- 순서 / 관계가 있는 배열에는 어울리지 않음
- hash function의 의존도가 높다. (해시 함수가 복잡하다면 hash를 만들어 내는데 오래걸릴 )
참조
선형 구조 - Array(배열), (Array)List(순차 리스트), LinkedList(연결 리스트)
정의같은 타입의 변수들로 이루어진 유한 집합논리적인 순서와 물리적인 순서가 같은 구조Element(요소) 배열을 구성하는 각각의 값Index(인덱스) 배열에서의 위치를 가리키는 숫자 값에 대한 유일
velog.io
선형 구조 - 스택, 큐, 덱
데이터 값을 저장하는 기본적인 구조로 일차원의 선형(linear) 자료 구조 이다.(배열/리스트와 유사하게) 값을 저장하는 연산과 저장된 값을 거내는 연산이 제공 된다.그러나, 매우 제한적인 규칙
velog.io
https://leejinseop.tistory.com/43
[자료구조] 그래프(Graph)의 개념 설명
1. 그래프 그래프(Graph)는 연결되어있는 원소간의 관계를 표현한 자료구조입니다. · 그래프는 연결할 객체를 나타내는 정점(Vertext)과 객체를 연결하는 간선(Edge)의 집합으로 구성됩니다. · 그래
leejinseop.tistory.com
https://velog.io/@yuseogi0218/Hash-%ED%95%B4%EC%8B%9C
Hash (해시)
데이터를 효율적으로 관리하기 위해, 임의의 길이 데이터를 고정된 길이의 데이터로 매핑하는 것해시 함수를 구현하여 데이터 값을 해시 값으로 매핑한다.정의key를 고정된 길이의 Hash로 변경해
velog.io
'Python' 카테고리의 다른 글
| Python 자료타입 (0) | 2024.01.16 |
|---|

댓글